



Pražské počátky humanizace psychiatrické péče v habsburské monarchii
V létě 1843 se na cestu do Prahy vydal Michael Viszánik, primář a ředitel vídeňského ústavu choromyslných, jak se…
Data, která dnes zaplňují paměťové karty našich zařízení a hrozí provalením našich největších tajemství, mohou být zároveň nedocenitelná pro zkoumání společenských a kulturních pohybů.
Jak pro budoucnost uchovat alespoň jejich část

Největší personální výplach v české kinematografii nepřišel s nacistickou okupací ani se začátkem normalizace. Proběhl na začátku devadesátých let, bezprostředně po revoluci, v důsledku krachu státní produkce a útlumu natáčení. Rok 1990 byl posledním pro čtvrtinu tehdy aktivních filmařů a filmařek. To je třikrát větší podíl končících než v černých letech 1938 a 1968.
V roce 2023 jsem strávil tři a půl hodiny v Moravské zemské knihovně a tři hodiny v Knihovně Jiřího Mahena. Naproti tomu v pivnici U Tekutého chleba jsem proseděl 89 hodin, v obchodním domě IKEA jsem bloumal téměř 24 hodin a v Lidlu jsem nakupoval 12 hodin.
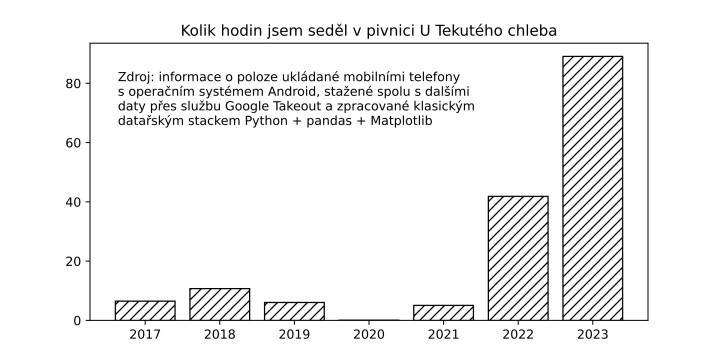
První statistika vychází z databáze Filmový přehled, udržované Národním filmovým archivem. Jde o pracně zdigitalizované analogové prameny: distribuční materiály, titulky, ročenky. Nepřistupoval jsem k této databázi jako filmový historik, ale jako datový novinář Samizdatu, datového týmu Českého rozhlasu. Nicméně ani jako laik jsem si v posledních letech nemohl nevšimnout, že historická věda má datovou analýzu a programování speciálních nástrojů ve svém šuplíku s nářadím už dlouho. Běžně narážím na materiály postavené na starých sčítáních lidu a na strojovém zpracování mnoha dalších archivních zdrojů. Skenují se a zpřístupňují pro fulltextové vyhledávání staré tisky, úřední listiny a rukopisy. Analyzují se letecké snímky i DNA. Různé metody strojového učení pomáhají přečíst zašifrované, poničené či úmyslně znehodnocené nosiče informací.
Za druhou statistiku vděčím tomu, že s sebou nosím v kapse telefon neustále šmírující moji polohu pro „zdokonalování služeb“, tedy pro zobrazování účinnějších reklam, a že mi GDPR zaručuje právo stáhnout si svá soukromá data z cloudu k sobě do počítače.
Právě tenhle rozměr dat coby historického pramene mi přijde přehlížený, ačkoliv je stále akutnější. Řeč na něj přichází obvykle jen v humorné nadsázce. „Kdyby žil Franz Kafka dnes, jak by vypadal jeho Instagram?“ řešil například panel literárního podcastu Lit při spisovatelovu červnovém výročí.
Kdyby žil Franz Kafka dnes, možná by Instagram neměl. Skoro určitě by ale měl mobilní telefon zaznamenávající polohu. Používal by e-mail a platební kartu. Kdykoliv by vyšel z bytu, jeho tvář by zaznamenala bezpečnostní kamera ještě na chodbě činžáku a pak co pár kroků palubní kamery v automobilech a sportovní kamery na přilbách cyklistů. Během své pracovní doby v pojišťovně by nejspíš nevydržel s nikým nechatovat, pozoruhodná by jistě byla i jeho pracovní korespondence v Outlooku nebo na Slacku, či dokonce excelovské tabulky s jeho propočty rizik. Dost možná by svůj zdravotní stav sledoval chytrými hodinkami.

Skutečný Kafka pověřil likvidací své pozůstalosti Maxe Broda, který nakonec svolil část děl z Kafkova šuplíku vydat. I kdyby byl dnešní Brod sebeodhodlanější nenechat na světě po Kafkovi ani písmenko, byl by to nadlidský úkol. Malý díl kafkovských archivů by se snad podařilo vymazat z cloudu docela. Větší část by si do té doby stáhl a zarchivoval třeba další účastník hromadných chatů. O největší části těchto dat by se Kafka nebo jím pověřený likvidátor nikdy neměl šanci dozvědět. Zároveň by toho ale spousta prostě zmizela: paměťové karty kamer by přepsal nový záznam, kapacita cloudových úložišť by se promazala po krachu provozovatelů jednotlivých aplikací.
Dějiny současnosti zaznamenáváme v o mnoho řádů jemnějším rozlišení než dějiny kterékoliv předchozí éry. A to převážně bezpracně, automaticky, často bez našeho vědomí, někdy proti naší vůli. Pikanterie ze životů velikánů jsou nakonec tím méně zajímavým v obřích archivech, které v haldách šumu zachycují každý společenský i kulturní pohyb a jsou schopny poskytnout explicitní odpovědi na otázky, ke kterým jsme se dosud byli zvyklí dobírat nepřímo, extrapolací kusých pramenů.
Na serverech Spotify zůstává uložená informace o tom, kdy a kde si některý ze stovek milionů uživatelů a uživatelek pustil konkrétní píseň. Netflix ví, ve které minutě a sekundě lidé přestávají sledovat filmy a seriály, Amazon zase, na které stránce odkládají elektronické knihy. V databázích obchodních řetězců zůstávají miliardy účtenek z nákupů potravin a jiného zboží. Několik málo provozovatelů sociálních sítí archivuje významnou část veškeré mezilidské komunikace. Několik výrobců sportovních hodinek ví o každém úderu srdcí stovek milionů lidí.
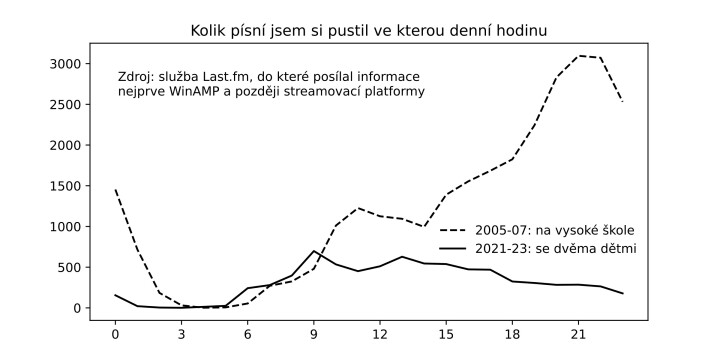
Neodhaluji teď nic tajného. Korporace samotné se daty, která sbírají, rády chlubívají. Pornhub si dělá reklamu každoročními statistikami, na co kde lidé nejčastěji koukají. Google se jednu dobu pokoušel predikovat šíření chřipky podle toho, kde lidé zrovna hledají její příznaky. Často – a po právu – se o zaznamenávání privátních údajů píše v souvislosti s ochranou soukromí a například s právem na to být zapomenuti.
Stavím proti němu právo na historickou paměť. U zažitějších pramenů jsme tato dvě práva vybalancovali: živé matriční knihy lze prohlížet pouze na úřadech, a to jedině s nějakým objektivním důvodem a pod dohledem, kdežto ty z devatenáctého století visí na webu. Také se nám, byť s velkými rezervami, daří pro budoucnost uchovávat ten digitální obsah, u kterého není co balancovat, tedy který nikomu nezasahuje do soukromí ani obchodních zájmů. Kopie webových stránek zůstávají uložené v Internet Archive nebo Webarchivu Národní knihovny, u programového kódu se o totéž pokouší Software Heritage.
Politické opatření, které by pro budoucí, ne-li dokonce pro současné bádání zpřístupnilo databáze nejrůznějších webových služeb, leží na nejvzdálenějších koncích představivosti. Bylo by těžko uskutečnitelné technologicky, ekonomicky i společensky. Než se něco takového stane, a ono se to spíš nestane, zbývá nám jiná do it yourself možnost: budovat svoje vlastní archivy. Přistupovat k datům, která o nás služby sbírají, podobně jako k rodinným fotografiím. Možná jednou někomu přijdou cenné, třeba ještě nám samotným, až služby zkrachují nebo nás právem či neprávem zablokují pro porušení podmínek. Kolečko klikání na tlačítka „Stáhnout všechna data“ a následné kopírování na záložní disk(y) není nijak nesnesitelné a lze jej podstoupit i s rizikem, že jde o zbytečný a sebestředný podnik.
Tato data jsou obvykle nabízena v nějakém tabulkovém formátu a jde je tedy otevřít i v Excelu. Nevadí, jestli s nimi neumíte dále pracovat: časem se to můžete naučit, časem můžou být užitečná někomu jinému, časem se třeba objeví reálně použitelné nástroje využívající umělou inteligenci, se kterými bude možné o obsahu tabulek konverzovat.
Druhým levelem je archivovat i data, která se netýkají přímo nás. Nemyslím tím soukromá data ostatních lidí, ale veřejně dostupné informace podléhající rychlé zkáze. Hlavně ty, které budou zpětně nejhodnotnější při zachycení v mnohem kratších intervalech, než v jakým web prochází a ukládá robot Web Archive.
Staré jízdní řády schraňované jedním fanouškem hromadné dopravy nám v datovém týmu ČRo před dvěma lety pomohly upozornit na to, že se intervaly brněnských linek po Covidu nevrátily k předpandemické četnosti. Sám automaticky a pravidelně stahuju informace o hodnocení české knižní produkce na několika čtenářských platformách nebo nabídky poledních menu v restauracích. Už po pár měsících sbírání z nich lze zjišťovat první zajímavé věci: višně se na lístcích ještě víc než v čase sklizně objevují v týdnu kolem svatého Valentýna a pátek navzdory povídačkám o likvidaci zbytků nebývá dnem hrstkové polévky a mletých mas, ale řízků. Po pár letech mohou být taková data nedocenitelná, protože zachytí proměny čtenářských i strávnických zvyků a umožní ověřit hypotézy, které dnes třeba ani nepřicházejí na mysl.
Sběr dat z webu nevyžaduje velké programátorské schopnosti, člověk si vystačí s krátkým YouTube kurzem nebo snad i se základy z gymplu, zvlášť když je po ruce ChatGPT pro konzultace nebo i pro generování kódu. Je to spíš zdlouhavá piplačka, spočívající v přemýšlení nad tím, co přesně stahovat, jak často, jak obelstít různé ochrany proti robotům a jak včas odhalit chyby. I proto se rád podělím o svůj seznam toho, co dalšího mám v plánu archivovat: nabídky nemovitostí a práce, programy kulturních center, „právě hrajeme“ na webovkách rádií, výjezdy hasičů, letáky supermarketů, katalogy podcastů. Mít dnes cokoliv z toho k dispozici pro sebe nezajímavější historickou éru (pokud to tedy v ní již existovalo), a navíc ve strojově čitelném formátu by bylo požehnáním – a my můžeme takto požehnat budoucím pokolením.

O významu i o praktických aspektech „pirátského archivaření“ píše pirátská archivářka Anna: https://annas-archive.se/blog/blog-how-to-become-a-pirate-archivist.html.
Jak proměňovat obsah webových stránek na dále zpracovatelné tabulky, popisuje kniha Python Web Scraping Cookbook Michaela Heydta. A také spousta videí na YouTube; doporučuji především obsah z kanálu freeCodeCamp.org.
Stačí-li vám ukládat obsah webu k sobě na disk a zpracování necháte na jiných, mohu doporučit nástroje Monolith (https://github.com/Y2Z/monolith) a yt-dlp (https://github.com/yt-dlp/yt-dlp). První ukládá celé webovky, včetně obrázků a skriptů, druhý umí extrahovat video a audio i z webů, které tomu aktivně brání. Oba dva se ovládají z příkazové řádky, tím pádem se i snadno automatizují.
Michal Kašpárek (* 1984) pracuje v Samizdatu, datovém týmu Českého rozhlasu. V roce 2023 mu vyšel román Fosilie. Jeho starší projekty lze najít na michalkasparek.cz.
This content was created as part of the Perspectives – the new label for independent, constructive and multi-perspective journalism. PERSPECTIVES is co-financed by the EU and implemented by a transnational editorial network from Central-Eastern Europe under the leadership of Goethe-Institut. Find out more about PERSPECTIVES: goethe.de/perspectives_eu.
Co-funded by the European Union. Views and opinions expressed are, however, those of the author(s) only and do not necessarily reflect those of the European Union or the European Commission. Neither the European Union nor the granting authority can be held responsible.
![]()
![]()

Číslo 125
Zvolte podporu, která je Vám nejbližší! Revue Prostor roste – a s tím i naše odpovědnost. Rádi bychom, aby naše platforma zůstala otevřená a přístupná všem.
Díky Vaší podpoře můžeme dále publikovat kvalitní autorské texty, férově odměňovat naše spolupracující a budovat udržitelný model, který drží nezávislou žurnalistiku při životě.
V létě 1843 se na cestu do Prahy vydal Michael Viszánik, primář a ředitel vídeňského ústavu choromyslných, jak se…

„Jako teenager jsem působila v Budějovickém Majálesu, narazila jsem občas na to, že se tady k mladým nepřistupuje…

Jak zůstat občansky aktivní i za války? Potíže hlavního ukrajinského města neztrácejí na naléhavosti ani dnes &ndash…

71 %. Takovou plochu naší planety zabírá otevřená voda, ale jen zhruba 5 % je zevrubněji prozkoumáno člověkem. Není…

„Psychické a fyzické projevy PMS* a PMDD se zdvojnásobí, když je to něco, za co se mám stydět a tajit to. Protože…

Rakouský Wiener Festwochen patří k nejsledovanějším divadelním festivalům svého druhu. Elitní kuratelu…

Do svých osmnácti jsem se svými spolužáky ze základky strávil v podstatě polovinu života. Dennodenně jsme se vídali…

Sexuální potřeby jsou plnohodnotnou součástí života stejně jako potřeba spánku, jídla nebo dýchání. A bylo by mylné je…

„Český film mě neprovokuje, nechává mě lhostejným, je takový korektní. A to je něco, co mě na něm štve nejvíc,…

Jak to zní, když dospíváte v současné Evropě?

An Iranian journalist in Vilnius follows the news from her home country as it moves through a historic and deadly…

Karlovarské lázně jsou místem, kde se geologické pohyby protínají se středověkými legendami a specifickou kulturou…
„Pro mě byla zásadní a důležitá informace, že nejnovější vakcína pokrývá devět druhů HPV virů. Ne všechny…